Ethereum Merge: Run the majority client at your own peril!
Special thanks to Vitalik Buterin, Hsiao-Wei Wang and Caspar Schwarz-Schilling for feedback and review.
Note (2025): This post was written before The Merge (September 2022). The Merge has since happened successfully. The Ethereum community has made significant progress on client diversity: Prysm no longer holds a 2/3 supermajority on the consensus side, and the execution client landscape has diversified beyond Go-ethereum. The analysis and incentive arguments in this post remain valid, and client diversity continues to be important.
TL;DR: For reasons of both safety and liveness, Ethereum has chosen a multi-client architecture. In order to encourage stakers to diversify their setups, penalties are higher for correlated failures. A staker running a minority client will thus typically only lose moderate amounts should their client have a bug, but running a majority client can incur a total loss. Responsible stakers should therefore look at the client landscape and choose a less popular client.
Why do we need multiple clients?
There are arguments why a single client architecture would be preferable. Developing multiple clients incurs a substantial overhead, which is the reason why we haven’t seen any other blockchain network seriously pursue the multi-client option.
So why does Ethereum aim to be multi-client? Clients are very complex pieces of code and likely contain bugs. The worst of these are so called “consensus bugs”, bugs in the core state transition logic of the blockchain. One often quoted example of this is the so-called “infinite money supply” bug, in which a buggy client accepts a transaction printing arbitrary amounts of Ether. If someone finds such a bug and isn’t stopped before they get to the exit doors (i.e. making use of the funds by sending them through a mixer or to an exchange), it would massively crash the value of Ether.
If everyone runs the same client, stopping this requires manual intervention, because the chain, all smart contracts and exchanges will keep running as usual. Even a few minutes could be enough to execute a successful attack and sufficiently disperse the funds to make it impossible to roll back only the attacker’s transactions. Depending on the amount of ETH printed, the community would likely coordinate on rolling back the chain to before the exploit (after having identified and fixed the bug).
Now let’s have a look at what happens when we have multiple clients. There are two possible cases:
-
The client with the bug represents less than 50% of the stake. The client will produce a block with the transaction exploiting the bug, printing ETH. Let’s call this chain A.
However, the majority of stake running a non-faulty client will ignore this block, because it is invalid (to them the printing ETH operation is simply invalid). They will build an alternative chain B that does not contain the invalid block.
Since the correct clients are in the majority, chain B will accumulate more attestations. Hence, even the buggy client will vote for chain B; as a result chain B will accumulate 100% of the votes and chain A will die. The chain will continue as if the bug never happened.
-
The majority of stake uses the buggy client. In this case, chain A will accumulate the majority of votes. But since B has less than 50% of all attestations, the offending client will never see a reason to switch from chain A to chain B. We will thus see a chain split.
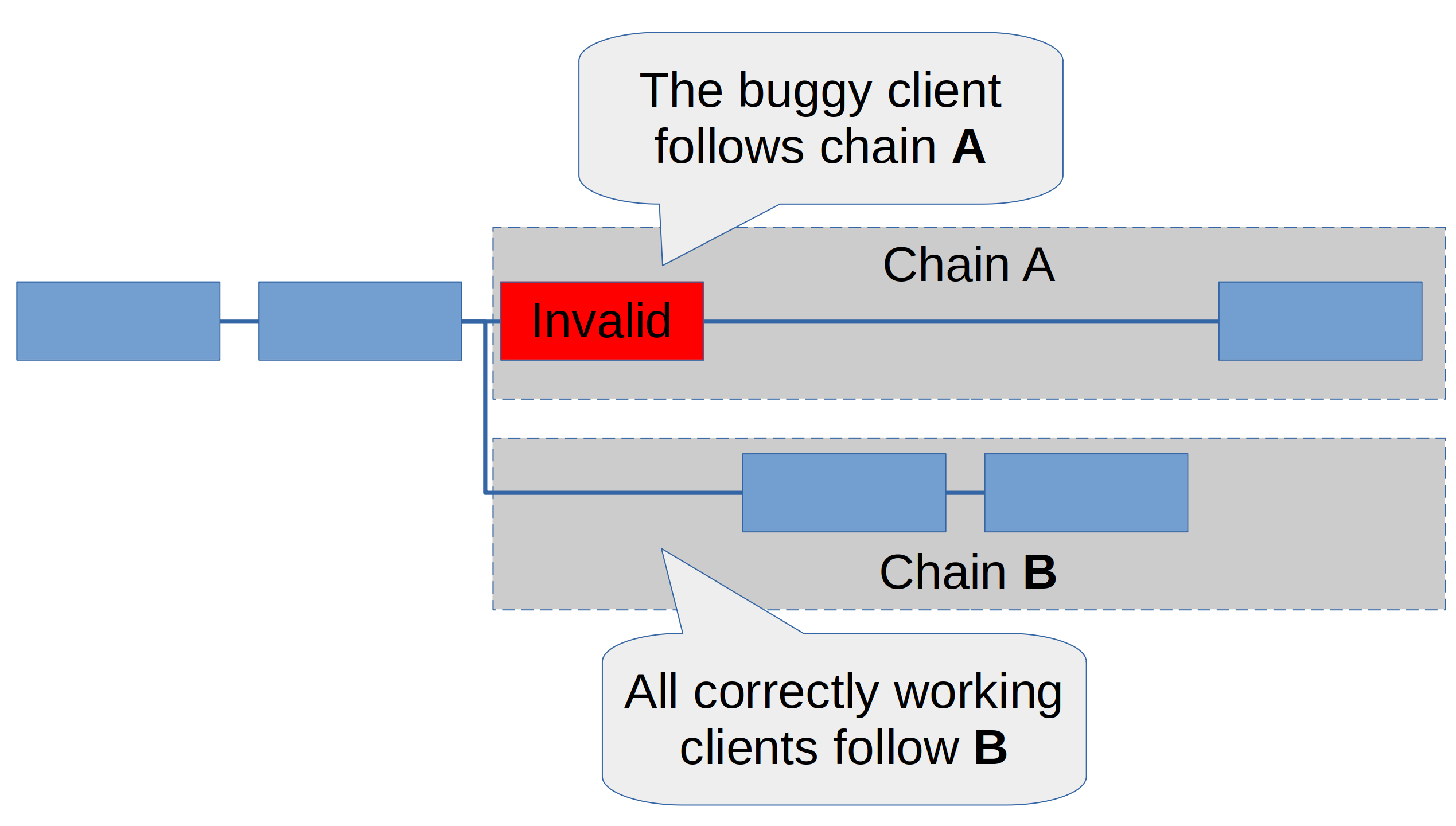
Case 1 is the ideal case. It would most likely lead to a single orphaned block which most users wouldn’t even notice. Devs can debug the client, fix the bug, and everything is great. Case 2 is clearly less than ideal, but still a better outcome than if there’s only a single client – most people would very quickly detect that there is a chain split (you can do this automatically by running several clients), exchanges would quickly suspend deposits, Defi users could tread carefully while the split is resolved. Basically, compared to the single client architecture, this still gives us a big flashing red warning light that allows to protect against the worst outcomes.
Case 2 will be much worse if the buggy client is run by more than 2/3 of the stake, in which case it would be finalizing the invalid chain. More on that later.
Some people think a chain split is so catastrophic that in itself it is an argument for a single-client architecture. But note that the chain split only happened because of a bug in the client. With a single client, if you wanted to fix this and return the chain back to status quo ante, you would have to roll back to the block before the bug happened – that’s just as bad as the chain split! So as bad as a chain split sounds, in the case where there is a critical bug in a client, it’s actually a feature, not a bug. At least you can see that something is seriously wrong.
Incentivising client diversity: anti-correlation penalties
It is clearly good for the network if the stake is split across multiple clients, with the best case being each client owning less than 1/3 of the total stake. This will make it resilient against a bug in any individual client. But why would stakers care? If there aren’t any incentives by the network, it’s unlikely that they will take on the cost of switching to a minority client.
Unfortunately we can’t make rewards directly dependent on what client a validator runs. There is no objective way to measure this that can’t be spoofed.
However, you can’t hide when your client has a bug. And this is where anti-correlation penalties come in: The idea is that if your validator does something bad, then the penalty is higher if more validators make a mistake around the same time. In other words, you get punished for correlated failures.
In Ethereum, you can currently get slashed for two behaviours:
- Signing two blocks at the same height
- Creating a pair of slashable attestations (surround or double votes)
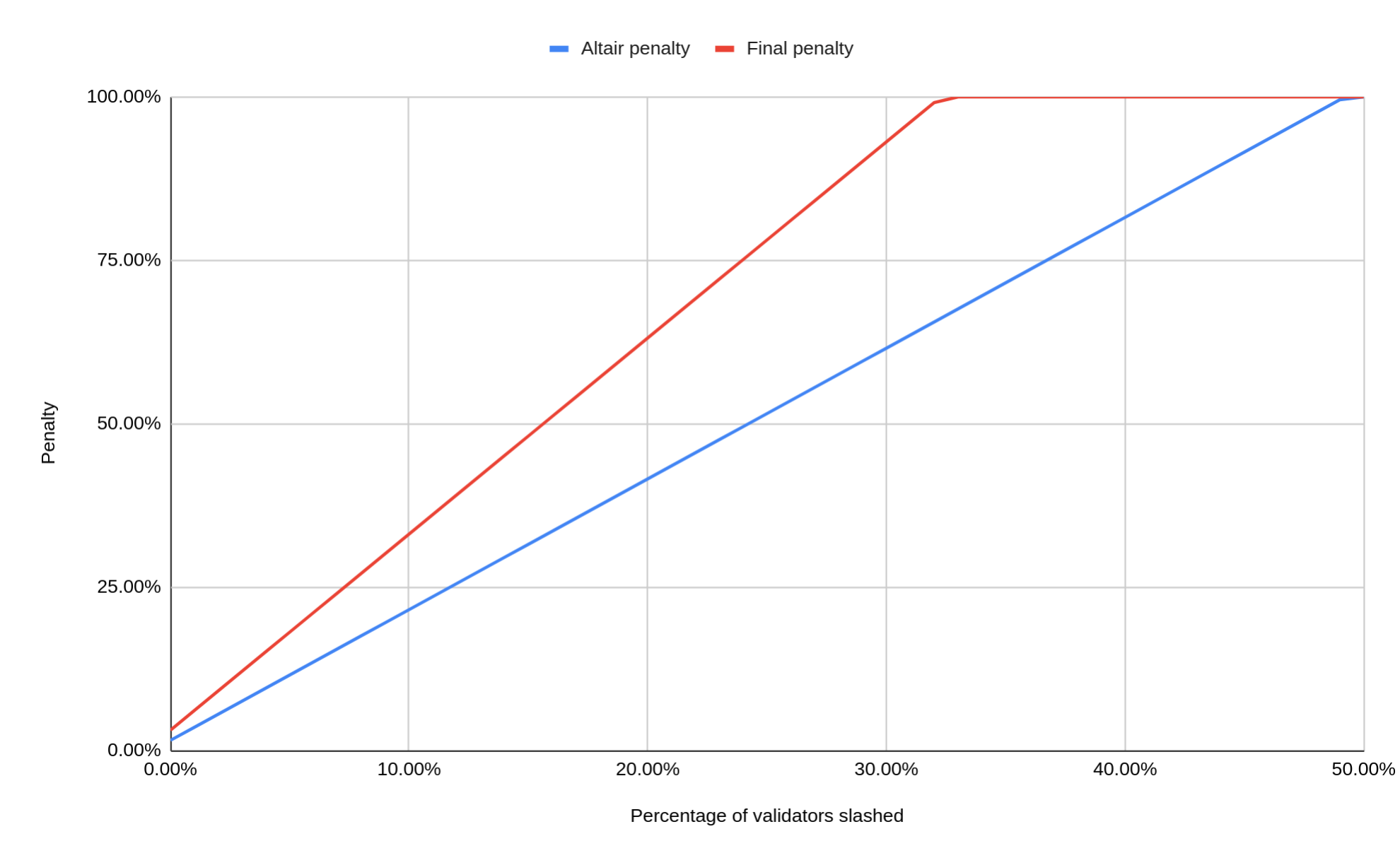
When you get slashed, you don’t usually lose all your funds. At the time of this writing (Altair fork), the default penalty is actually quite small: You would only lose 0.5 ETH, or about 1.5% of your staked Ether (ultimately this will be increased to 1 ETH or 3%).
However, there is a catch: There is an additional penalty that is dependent on all other slashings that occur during the 4096 epochs (18 days) before and after your validator was slashed. You are further penalized by an amount that is proportional to the total amount slashed during this period.
This can be a much larger penalty than the initial penalty. Currently (Altair fork) it is set so that if more than half of the full staking balance got slashed during this period, then you will lose all your funds. Ultimately this will be set so that you will lose all of your stake if 1/3 of other validators got slashed. 1/3 was chosen because this is the minimum amount of the stake that has to equivocate in order to create a consensus failure.
The other anti-correlation penalty: The quadratic inactivity leak
Another way a validator can fail is by being offline. Again there is a penalty for it, but its mechanism is very different. We do not call it slashing, and it’s usually small: Under normal operation, a validator that is offline is penalized by the same amount that they would be gaining if they were validating perfectly. At the time of this writing, this is 4.8% per year. It is probably not worth breaking a sweat if your validator is offline for a few hours or days, for example due to a temporary internet outage.
It becomes very different when more than 1/3 of all validators are offline. Then the beacon chain cannot finalize, which threatens a fundamental property of the consensus protocol, namely liveness.
To restore liveness in a scenario like this the so-called “quadratic inactivity leak” kicks in. The total penalty amount raises quadratically with time if a validator continues being offline while the chain is not finalizing. Initially it is very low; after ~4.5 days, the offline validators will lose 1% of their stake. However, it increases to 5% after ~10 days and to 20% after ~21 days (these are Altair values, they will be doubled in the future).
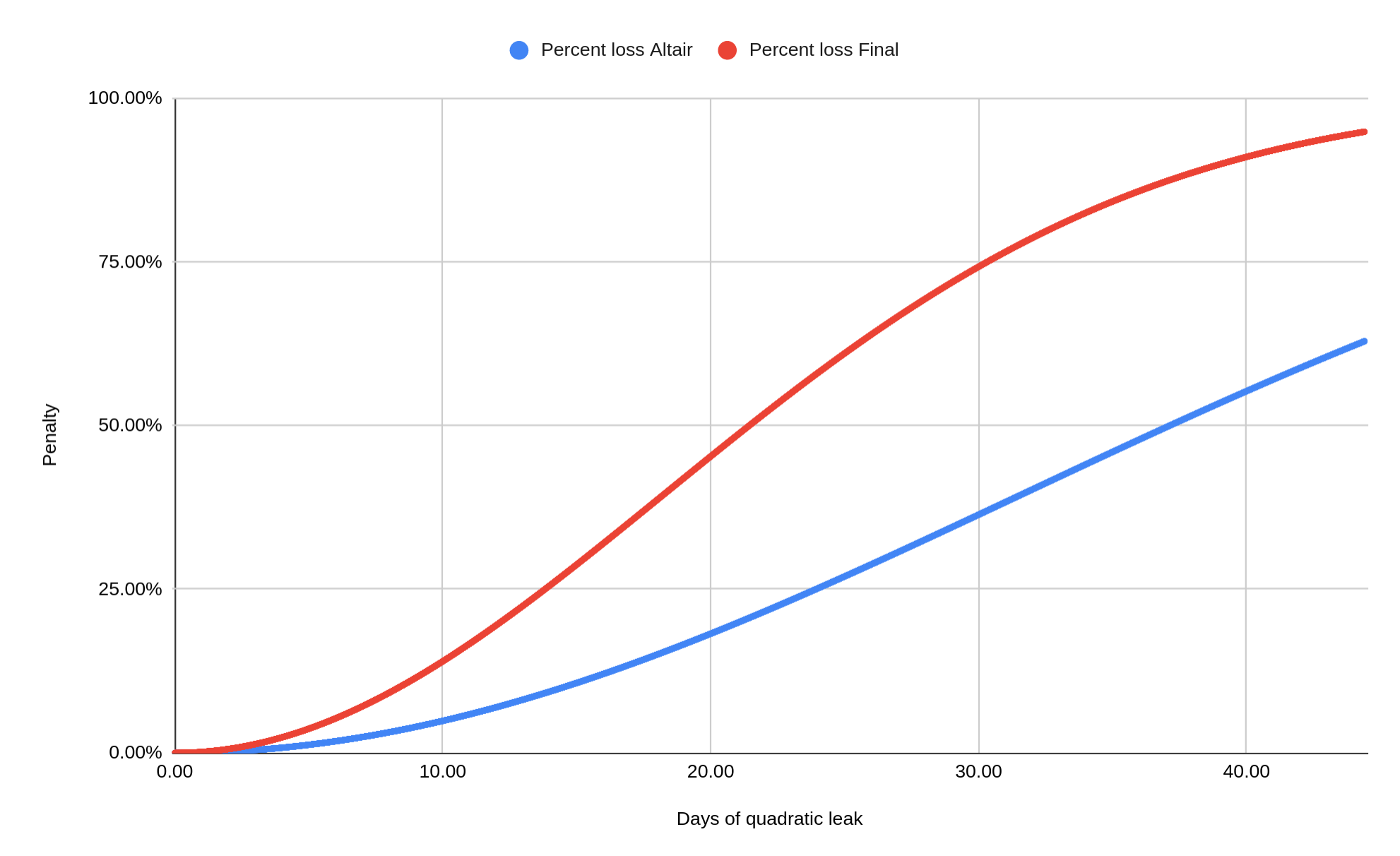
This mechanism is designed so that in the case of a catastrophic event that annihilates a large number of validator operations, the chain will eventually be able to finalize again. As the offline validators lose larger and larger parts of their stake, they will make up a smaller and smaller share of the total, and as their stake drops below 1/3, the remaining online validators gain the required 2/3-majority, allowing them to finalize the chain.
However, there is another case where this becomes relevant: In certain cases, validators cannot vote for the valid chain anymore because they accidentally locked themselves into an invalid chain. More on this below.
How bad is it to run the majority client?
In order to understand what the dangers are, let’s take a look at three failure types:
- Mass slashing event: Due to a bug, majority-client validators sign slashable attestations
- Mass offline event: Due to a bug, all majority-client validators go offline
- Invalid block event: Due to a bug, majority-client validators all attest to an invalid block
There are other kinds of mass failures and slashings that can happen, but I’m restricting myself to those related to client bugs (the ones you should consider when choosing which client to run).
Scenario 1: Double signing
This is probably the most feared scenario by most validator operators: A bug leading the validator client to sign slashable attestations. One example would be two attestations voting for the same target epoch, but with different payloads. Because it is a client bug, it’s not just one staker that is concerned, but all stakers that run this particular client. When the equivocations are detected, the slashings will be a bloodbath: All concerned stakers will lose 100% of their staked funds. This is because we are considering a majority client: If the stake of the concerned client were only 10%, then “only” about 20% of their stake would be slashed (in Altair; 30% with the final penalty parameters in place).
The damage in this case is clearly extreme, but I also think it is extremely unlikely. The conditions for slashable attestations are simple, and that’s why validator clients (VCs) were built to enforce them. The validator client is a small, well audited piece of software. A bug of this magnitude is unlikely.
We have seen some slashings so far, but as far as I know all of them where due to operator failures – almost all of them resulting from an operator running the same validator in several locations. Since these aren’t correlated, the slashing amounts are small.
Scenario 2: Mass offline event
For this scenario, we assume that the majority client has a bug, which when triggered, leads to a crash of the client. An offending block has been integrated into the chain, and whenever the client encounters that block, it goes offline, leaving it unable to participate any further in consensus. The majority client is now offline, so the inactivity leak kicks in.
Client developers will scramble to get things back together. Realistically within hours, at most in a few days, they will release a bug fix that will remove the crash.
In the meantime, stakers also have the option to simply switch to another client. As long as enough do this to get more than 2/3 of all validators online, the quadratic inactivity leak will stop. It is not unlikely that this will happen before there is a fix for the buggy client.
This scenario is not unlikely (bugs that lead to crashes are one of the most common types), but the total penalty would probably be less than 1% of the stake affected.
Scenario 3: Invalid block
For this scenario, we consider the case where the majority client has a bug that produces an invalid block, and also accepts it as valid – i.e. when other validators using the same client see the invalid block, they will consider it as valid, and hence attest to it.
Let’s call the chain that includes the invalid block chain A. As soon as the invalid block is produced, two things will happen:
- All correctly functioning clients will ignore the invalid block and instead build on the latest valid head producing a separate chain B. All correctly working clients will vote and build on chain B.
- The faulty client considers both chain A and B valid. It will thus vote for whichever of the two it currently sees as the heaviest chain.
We need to distinguish three cases:
-
The buggy client has less than 1/2 of total stake. In this case, all correct clients vote and build on chain B eventually making it the heaviest chain. At this point even the buggy client will switch to chain B. Other than one or a few orphaned blocks, nothing bad will happen. This is the happy case, and why it is great to only have sub-majority clients.
-
The buggy client has more than 1/2 and less than 2/3 of the stake. In this case, we will see two chains being built – A by the buggy client, and B by all other clients. Neither chain has a 2/3-majority and therefore they cannot finalize. As this happens, developers will scramble to understand why there are two chains. As they figure out that there is an invalid block in chain A, they can proceed to fix the buggy client. Once it is fixed, it will recognize chain A as invalid. It will thus start building on chain B, which will allow it to finalize. This is very disruptive for users. While hopefully the confusion between which chain is valid will be short and less than an hour, the chain probably won’t finalize for many hours, potentially even a day. But for stakers, even the ones running the buggy client, the penalties would still be relatively light. They will receive the “inactivity leak” penalty for not participating in chain B while they were building the invalid chain A. However, since this is likely less than a day, we are talking of a penalty that’s less than 1% of the stake.
-
The buggy client has more than 2/3 of the stake. In this case, the buggy client will not just build chain A – it will actually have enough stake to “finalize” it. Note that it will be the only client that will think that chain A is finalized. One of the conditions of finalization is that the chain is valid, and to all other correctly operating clients, chain A will be invalid. However, due to how the Casper FFG protocol works, when a validator has finalized chain A, they can never take part in another chain that is in conflict with A without getting slashed, unless that chain is finalized (for anyone interested in the details, see Appendix 2). So once chain A has been finalized, the validators running the buggy client are in a terrible bind: They have committed to chain A, but chain A is invalid. They cannot contribute to B because it hasn’t finalized yet. Even the bugfix to their validator software won’t help them – they have already sent the offending votes. What will happen now is very painful: Chain B, which is not finalizing, will go into the quadratic inactivity leak. Over several weeks, the offending validators will leak their stake until enough has been lost so that B will finalize again. Let’s say they started off with 70% of the stake – then they would lose 79% of their stake, because this is how much they would need to lose in order to represent less than 1/3 of the total stake. At this point, chain B will finalize again and all stakers can switch to it. The chain will be healthy again, but the disruption will have lasted weeks, and millions of ETH were destroyed in the process.
Clearly, case 3 is nothing short of a catastrophe. This is why we are extremely keen not to have any client with more than 2/3 of the stake. Then no invalid block can ever be finalized, and this can never happen.
Risk analysis
So how do we evaluate these scenarios? A typical risk analysis strategy is to evaluate the likelihood of an event happening (1 – extremely unlikely, 5 – quite likely) as well as the impact (1 – very low, 5 – catastrophic). The most important risks to focus on are those that score high on both metrics, represented by the product of impact and likelihood.
| Scenario | Likelihood | Impact | Product (Impact * Likelihood) |
|---|---|---|---|
| Scenario 1 | 1 | 5 | 5 |
| Scenario 2 | 4 | 2 | 8 |
| Scenario 3 | 3 | 5 | 15 |
Looking at this, by far the highest priority is scenario 3. The impact when one client is in a 2/3 supermajority is quite catastrophic, and it is also a relatively likely scenario. To highlight how easily such a bug can happen, a bug of this sort happened recently on the Kiln testnet (see Kiln testnet block proposal failure). In this case, Prysm did detect that the block was faulty after proposing it, and did not attest to it. Had Prysm considered that block as valid, and this had happened on mainnet, then we would be in the catastrophic case described in case 3 of scenario 3 – because Prysm currently has a 2/3 majority in mainnet. So if you are currently running Prysm, there is a very real risk that you could lose all your funds and you should consider switching clients.
Scenario 1, which people are probably most worried about, received a relatively low rating. The reason for this is that I consider the likelihood of it happening to be quite low, because I think that the Validator Client software is very well implemented in all clients and it is unlikely to produce slashable attestations or blocks.
What are my options, if I currently run the majority client and I’m worried about switching?
Switching clients can be a major undertaking. It also comes with some risks. What if the slashing database is not properly migrated to the new setup? There might be a risk of getting slashed, which completely defeats the purpose.
There is another option that I would suggest to anyone who is worried about this. It is also possible to leave your validator setup exactly as it is (no need to take those keys out etc.) and only switch the beacon node. This is extremely low risk because as long as the validator client is working as intended, it will never double sign and thus cannot be slashed. Especially if you have large operations, where changing the validator client (or remote signer) infrastructure would be very expensive and might require audits, this may be a good option. Should the setup perform less well than expected, it can also be easily switched back to the original client or another minority client can be tried.
The nice thing is that you have very little to worry about when switching your beacon node: The worst thing it can do to you is to be temporarily offline. That’s because the beacon node itself can never produce a slashable message on its own. And you can’t end up in scenario 3 if you’re running a minority client, because even if you would vote for an invalid block, that block would not get enough votes to be finalized.
How about the execution clients?
What I have written above applies to the Consensus clients – Prysm, Lighthouse, Nimbus, Lodestar and Teku, of which at the time of writing, Prysm likely has a 2/3 majority on the network.
All of this applies in the same way to the execution client. Should Go-ethereum, likely to be the majority execution client after the merge, produce an invalid block, it could get finalized and thus cause the catastrophic failure described in scenario 3.
Luckily, we now have three other execution clients ready for production – Nethermind, Besu and Erigon. If you are a staker, I highly recommend running one of these. If you are running a minority client, the risks are very low! But if you run the majority client, you are at serious risk of losing all your funds.
Appendix
A1: Why is there no slashing for invalid blocks?
In Scenario 3, we have to rely on the quadratic inactivity leak to punish validators for proposing and voting for an invalid block. That’s strange – why don’t we just punish them directly? It would be faster and less painful to watch.
There are actually two reasons why we don’t do this – one is that we currently can’t, but even if we could, we may well not do it:
-
Currently, it is practically impossible to introduce a penalty (“slashing”) for invalid blocks. The reason for this is that neither the beacon chain nor the execution chain are currently “stateless” – i.e. in order to check whether a block is valid, you need a context (the “state”) that is 100s of MB (beacon chain) or GB (execution chain) large. This means there is no “concise proof” that a block is invalid. We need such a proof to slash a validator: The block that “slashes” a validator needs to include a proof that the validator has made an offence. There are ways around this without having a stateless consensus, however it would involve much more complex constructions such as multi-round fraud proofs, such as Arbitrum is currently using for their rollup.
-
The second reason why we might not be that eager to introduce this type of slashing even if we could, is because producing invalid blocks is a much harder thing to protect against than the current slashing conditions. The current conditions are extremely simple and can be validated easily in a few lines of code by validator clients. This is why I consider scenario 1 above so unlikely – slashable messages have so far only been produced by operator failures, and I think that’s likely to remain the case. Adding slashing for producing invalid blocks (or attesting to them) raises the risks for stakers. Now even those running minority clients could risk serious penalties.
In summary, we are unlikely to see direct penalties for invalid blocks and/or attestations to them for the next few years.
A2: Why can’t the buggy client switch to chain B once it has finalized chain A?
This section is for anyone who wants to understand in more detail why the buggy client can’t just switch back and has to suffer the horrendous inactivity leak. For this we have to look how Casper FFG finalization works.
Each attestation contains a source and a target checkpoint. A checkpoint is the first block of an epoch. If there is a link from one epoch to another which has a total of >2/3 of all stake voting for it (i.e., there are this many attestations with the first checkpoint as the “source” and the second checkpoint as the “target”), then we call this a “supermajority link”.
An epoch can be “justified” and “finalized”. These are defined as follows:
- Epoch 0 is justified
- An epoch is justified if there is a supermajority link from a justified epoch.
- An epoch X is finalized if (1) the epoch X is justified and (2) the next epoch is also justified, with the source of the supermajority link being epoch X
Rule 3 is slightly simplified (there are more conditions under which an epoch can be finalized, but they aren’t important for this discussion). Now let’s come to the slashing conditions. There are two rules for slashing attestations. Both compare a pair of attestations V and W:
- They are slashable if the target of V and W is the same epoch (i.e. the same height), but they don’t vote for the same checkpoint (double vote)
- They are slashable if V “jumps over” W. What this means as that (1) the source of V is earlier than the source of W and (2) the target of V is later than the target of W (surround vote)
The first condition is obvious: It prevents simply voting for two different chains at the same height. But what does the second condition do?
Its function is to slash all validators that take part in finalizing two conflicting chains (which should never happen). To see why, let’s look at our scenario 3 again, in the worst case where the buggy client is in a supermajority (>2/3 of the stake). As it continues voting for the faulty chain, it will finalize the epoch with the invalid block, like this:
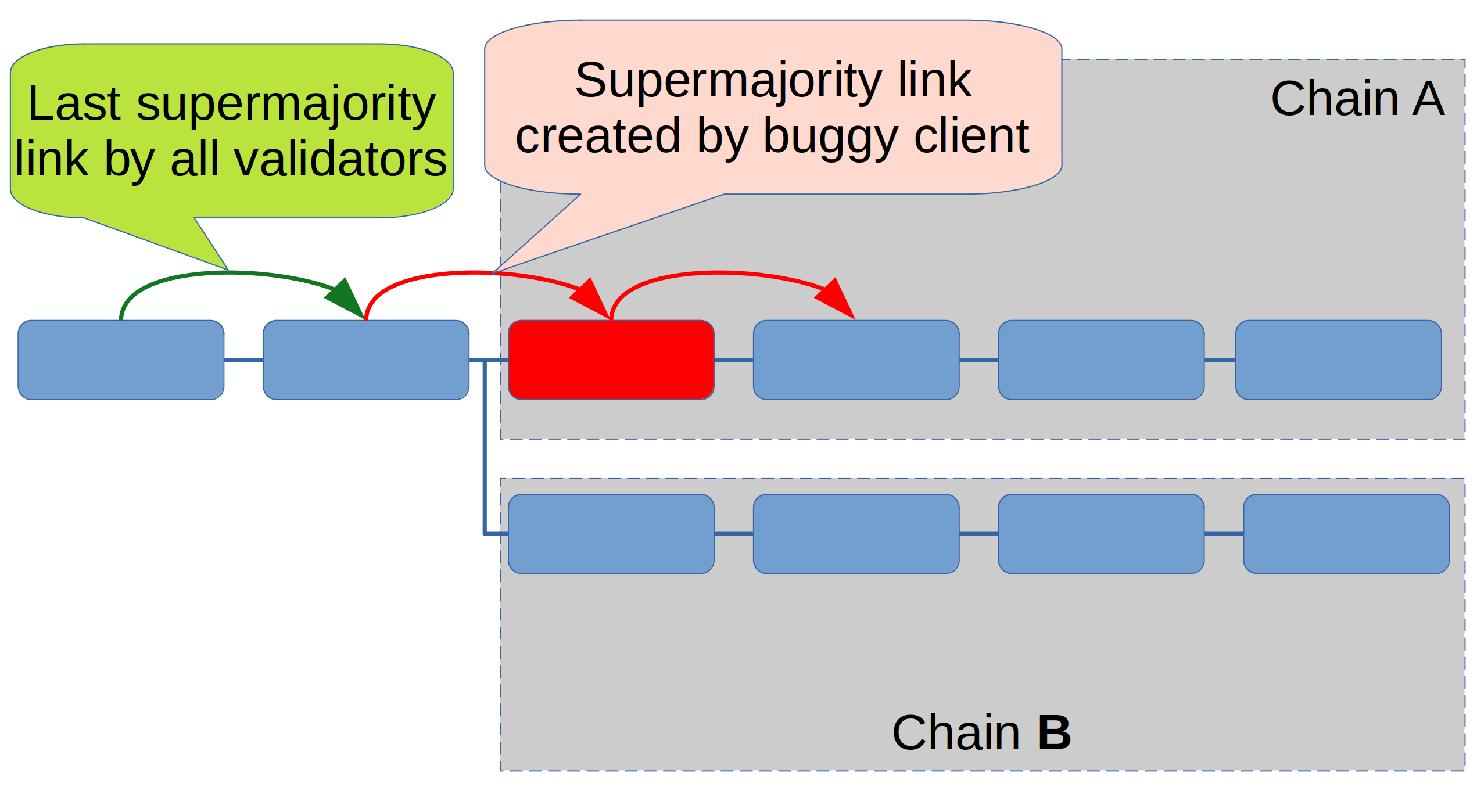
The rounded boxes in this picture represent epochs, not blocks. The green arrow is the last supermajority link created by all validators. The red arrows are supermajority links that were only supported by the buggy client. Correctly working clients ignore the epoch with the invalid block (red). The first red arrow will justify the invalid epoch, and the second one finalizes it.
Now let’s assume that the bug has been fixed and the validators that finalized the invalid epoch would like to rejoin the correct chain B. In order to be able to finalize the chain, a first step is to justify epoch X:
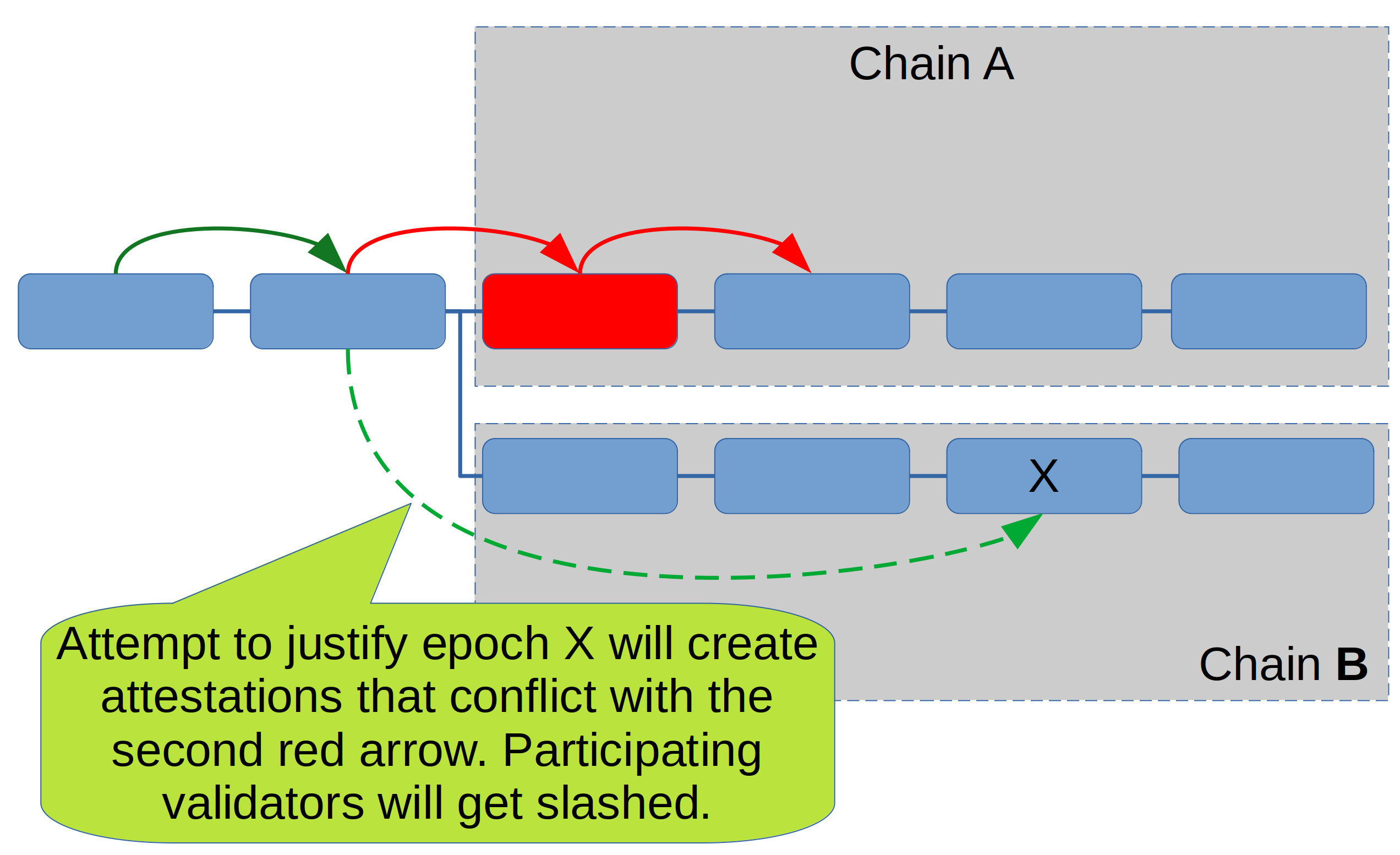
However, in order to participate in the justification of epoch X (which needs a supermajority link as indicated by the dashed green arrow), they would have to “jump over” the second red arrow – the one that finalized the invalid epoch. Voting for both of these links is a slashable offense.
This continues to be true for any later epoch. The only way it will get fixed is through the quadratic inactivity leak: As chain B grows, the locked out validators will leak their funds until chain B can be justified and finalized by the correctly working clients.
